|
|

|
|
|
[2025.01] We released DeQA-Score, a distribution-based depicted image quality assessment model for score regression. Datasets, codes, and model weights (full tuning / LoRA tuning) were available. |
|
*: Equal Contribution, †: Corresponding Author |
|
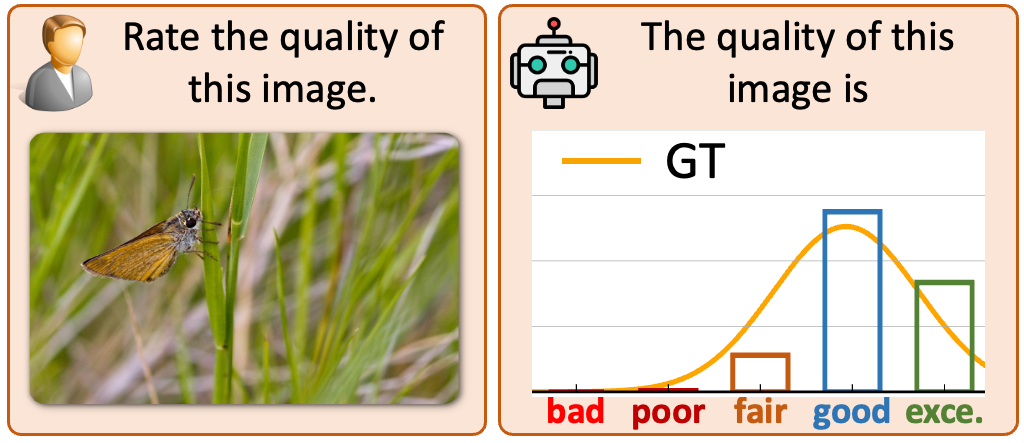
Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue†, Chao Dong† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 paper / project page / code / data We introduce DeQA-Score, a distribution-based depicted image quality assessment model for score regression. |

|
Zhiyuan You, Jinjin Gu, Xin Cai, Zheyuan Li, Kaiwen Zhu, Chao Dong†, Tianfan Xue† IEEE Transactions on Image Processing (TIP), 2025 paper / project page / code / data We introduce DepictQA-Wild, also named Enhanced DepictQA (EDQA), a multi-functional in-the-wild descriptive image quality assessment model. |

|
Zhiyuan You*, Zheyuan Li*, Jinjin Gu*, Zhenfei Yin, Tianfan Xue†, Chao Dong† European Conference on Computer Vision (ECCV), 2024 paper / project page / code / data We introduce DepictQA, leveraging Multi-modal Large Language Models, allowing for detailed, language-based, and human-like evaluation of image quality. |
|
Template from JonBarron |