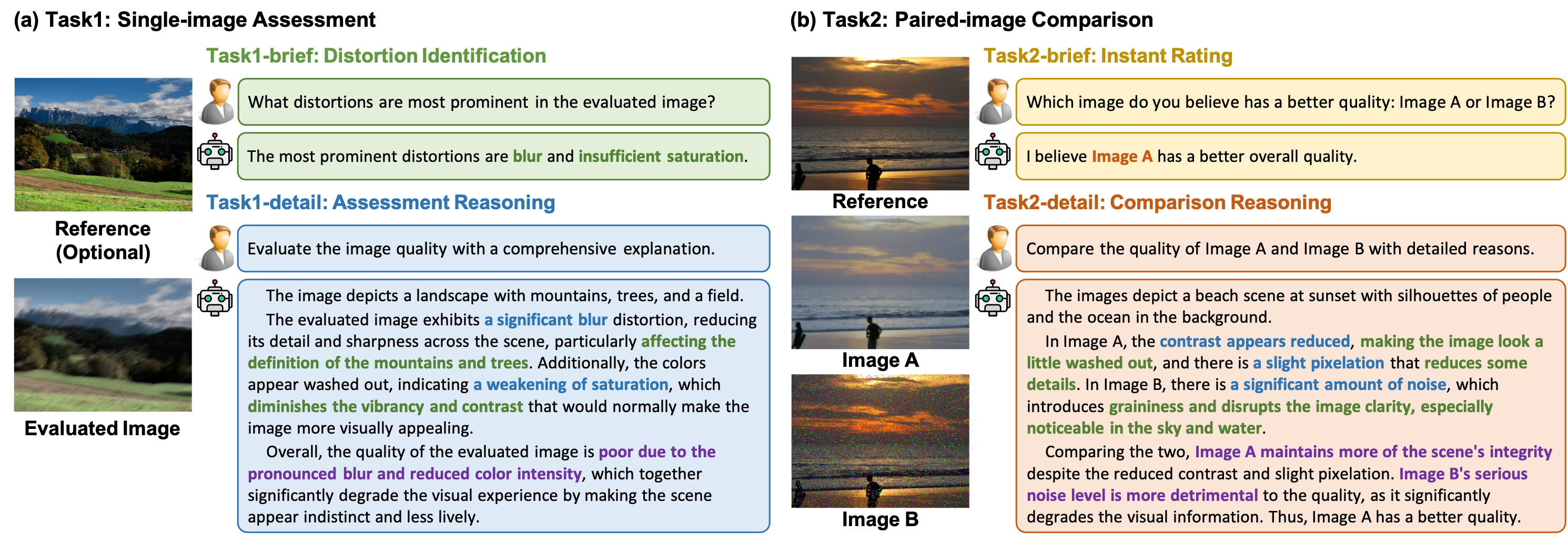
Multi-functional Task Paradigm of DepictQA-Wild
DepictQA-Wild focuses on two tasks including single-image assessment and paired-image comparison in both full-reference and non-reference settings. Each task contains a brief sub-task focusing on the fundamental IQA ability, and a detailed sub-task fostering the reasoning capacities.