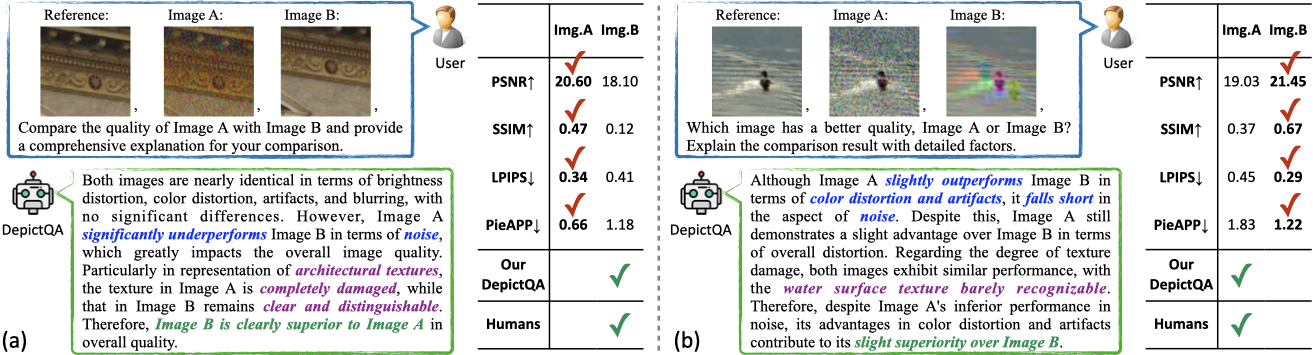
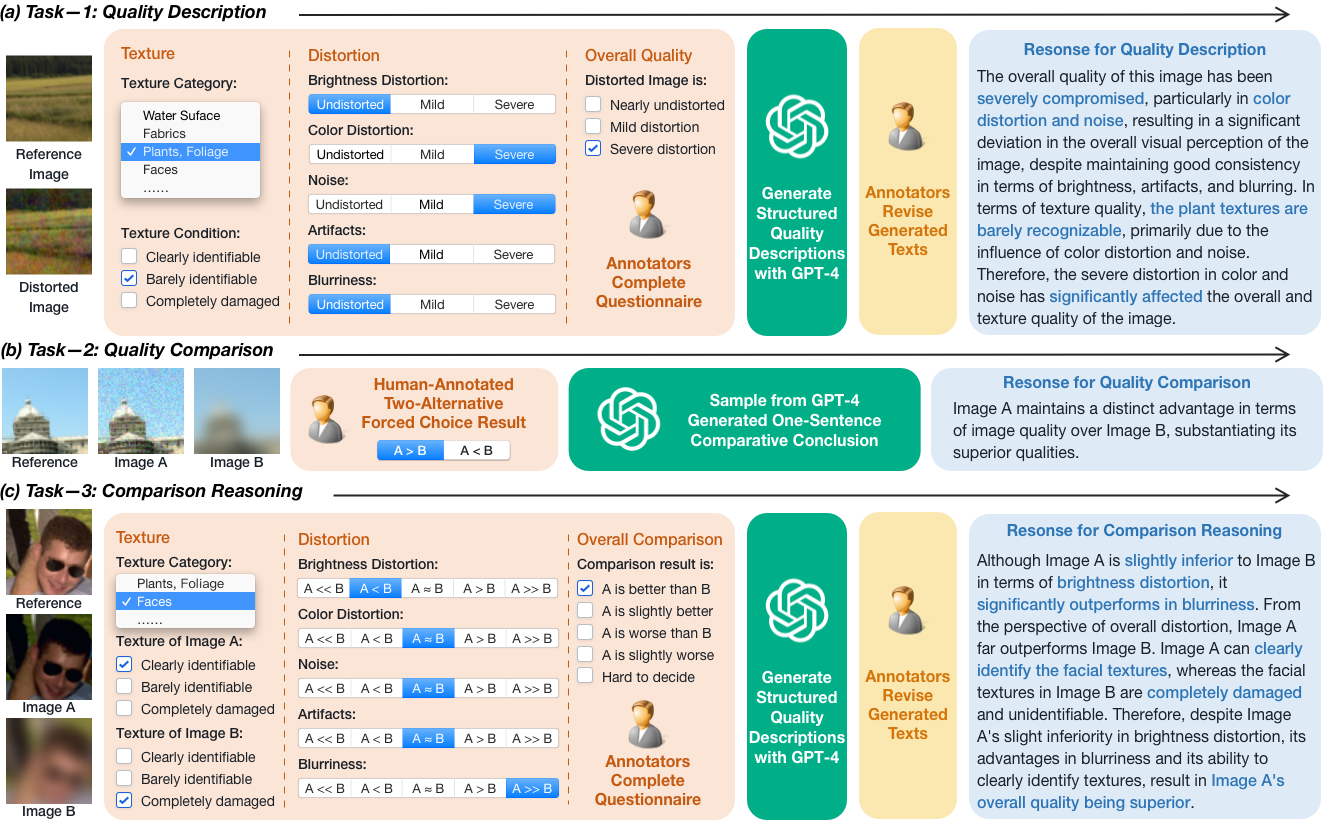
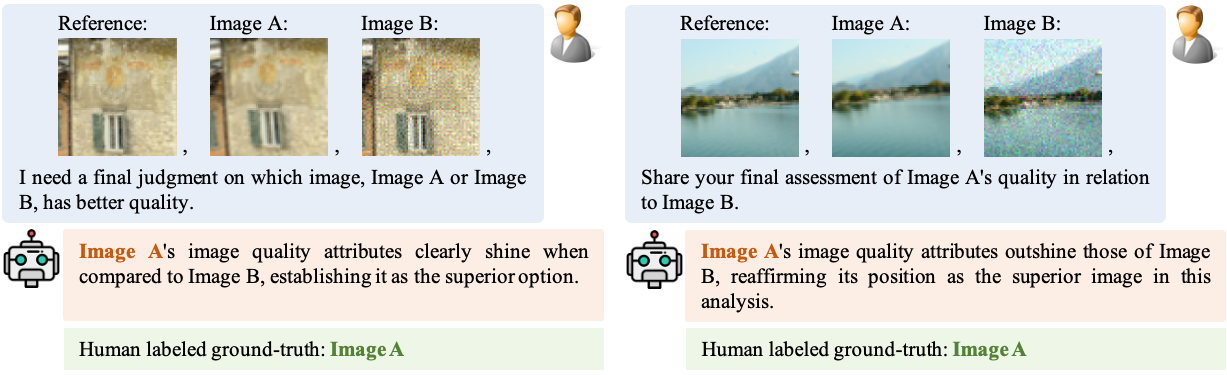
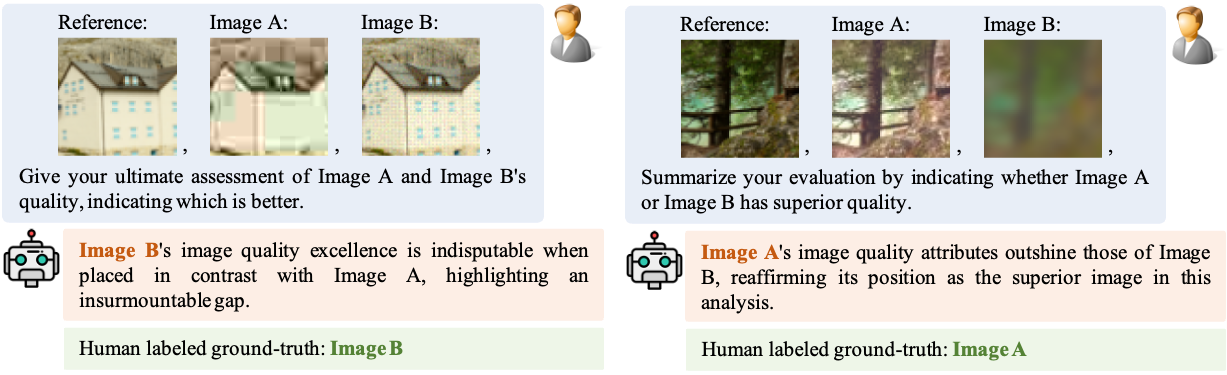
@article{depictqa_v2,
title={Descriptive Image Quality Assessment in the Wild},
author={You, Zhiyuan and Gu, Jinjin and Li, Zheyuan and Cai, Xin and Zhu, Kaiwen and Dong, Chao and Xue, Tianfan},
journal={arXiv preprint arXiv:2405.18842},
year={2024}
}
@article{depictqa_v1,
title={Depicting Beyond Scores: Advancing Image Quality Assessment through Multi-modal Language Models},
author={You, Zhiyuan and Li, Zheyuan, and Gu, Jinjin, and Yin, Zhenfei and Xue, Tianfan and Dong, Chao},
journal={arXiv preprint arXiv:2312.08962},
year={2023}
}